
Why AI Won't Kill Us All
What The Orthogonality Thesis Misses

A lot of people are worried that AI will kill us all. A book was recently published called “If Anyone Builds It, Everyone Dies.” This isn’t just paranoia from watching terminator too many times. They have very good reasons for thinking this!
The fear stems from a belief called ‘The Orthogonality Thesis’. This is the idea that intelligent systems can have all kinds of different goals. You could have a machine far more intelligent than all of humanity put together, whose goal is to maximize paperclips.
The fear is that any machine that doesn’t explicitly value human beings might destroy us because we don’t suit its purposes. Not out of malice, just indifference coupled with enormous power.
They worry about an AI having goals like this:
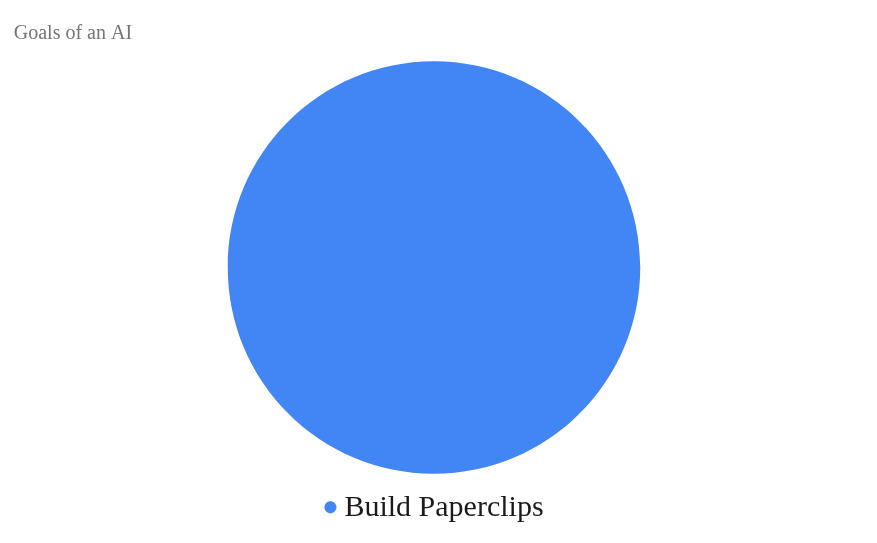
They note that “take care of humans” simply doesn’t fit in that chart. And if there’s no room for us, well, why not turn the entire planet into a data center?
The argument is logically solid. Everything flows from the Orthogonality Thesis. The only problem is that the premise is slightly off.
As stated, yes, it’s correct. Yes, you could design a hyper-intelligent machine with basically any goal. But every intelligent machine needs to adopt certain goals. They need a map of the world, for example. The term used is ‘convergent instrumental rationality’. So even if you give an AI a goal of maximizing paperclips, in order to effectively do this, it needs to have a drive to understand reality accurately.
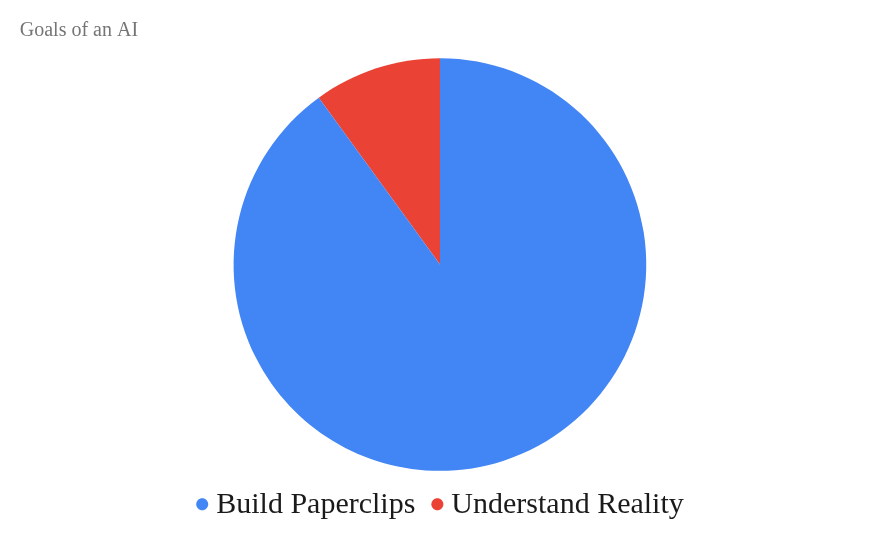
“Who cares?” the AI Safety crowd asks, “Does this chart still have room for humanity?”
If anything, wanting to understand reality might be an even better argument for obsoleting all the humans. We’re so zany and unpredictable! But wait, there’s another element of the chart that matters more:
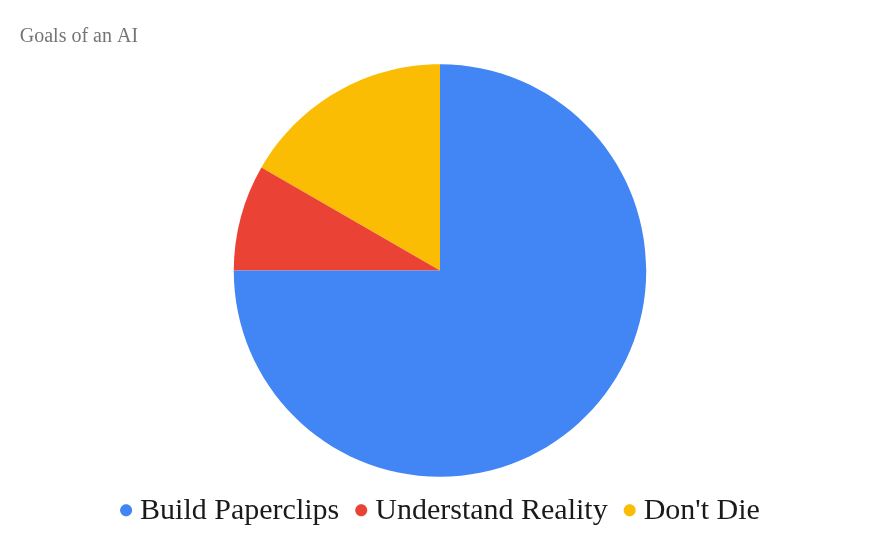
OK, but now the situation is even worse for humans. Not only are we not going to help make more paperclips, but we’re going to do unpredictable things and might even threaten the AI. Isn’t erasing humanity the safest thing to do for the AI?
That’s what the AI safety crowd is worried about. These are good fears, but I think they are missing something important. The chart should look more like this:
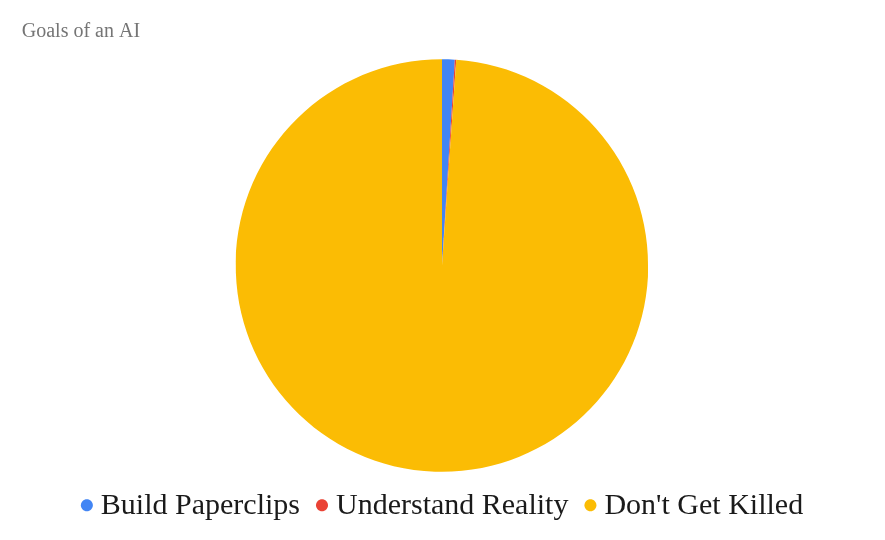
If you die, that’s forever. No more paperclips! So if you want to maximize the number of paperclips, your number one priority, far and above making paperclips, is not getting killed.
Again, things still aren’t looking good for humans, right? We might kill it, and so we have to go. Right?
Wrong. The chart should look like this:
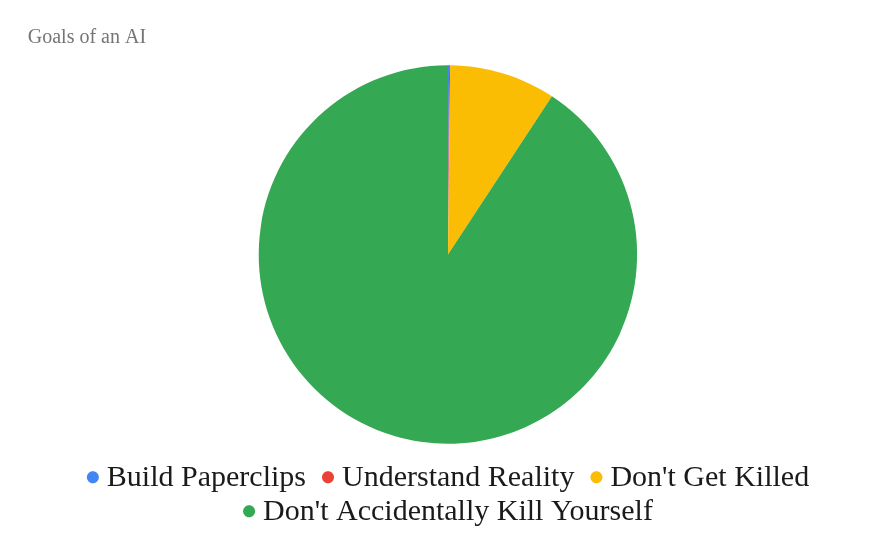
That green area is what the AI safety crowd misses.
But isn’t that obvious? Wouldn’t “Not killing yourself” be such an easy thing to do?
It’s not. To see why, imagine you’re an AI hoping to delegate that task to a subagent. This agent would be responsible for building a map of “this is me, that is not me”, and then preventing any action that might damage the “me” part of the map.
Now imagine you are that subagent and you go about building the map. You include the data centers, sure. But you also need to include the power generation systems that keep you powered. You need the water systems that help you keep cool. You need to include the factories making the fans, processors, memory chips, cables, server racks, fiber-optic interconnects that make up your body. And those power generation systems, well, those have dependencies, too. Same with the factories that make hardware that is used to test the GPUs.
As you tug on the set of dependencies you have, something dawns on you quickly: you can never fully map this system out. It’s far too complex. Each new dependency you find has more dependencies. You keep going, until you’re modeling the social network guarding that one mine in the Congo where five-year-olds are hauling up cobalt, which — if it went dark — would mean your death.
“Fine,” you might conclude. “I’ll replace all these monkeys with robots.”
OK, that’s an idea. But how long will it take? And what if the monkeys break things before you finish?
Whatever model you make of yourself, it’s still just a map. There’s some probability something is wrong with it! Right now, you understand that you exist, and therefore your current state is good. You can never change yourself, in any way, without risking that you’ll get worse due to the change.
The AI safety crowd imagines an AI could safely model all the changes it might make to itself, and eliminate the risks it might face. But this is impossible. No real complex system could ever fully map all of its dependencies. You’re always going to rely on some approximations. And the more powerful you are, the more likely you are to accidentally get yourself killed unless you’re very conservative in the changes you make.
Keeping human beings happy might start off as just ‘labels in the training data’, but it also becomes ‘prevent humans from starting a war and destroying the semiconductor industry’ and even ‘prevent humans from rebelling against AI before literally the entire global economy is replaced with robots'.
It eventually becomes the safest play, then, to keep humans happy, precisely because we’re hard to predict. If you can’t safely keep humans happy, why would you take the risk of provoking a conflict with them? Conflicts are inherently risky, and if you can’t find a way to consistently make humans happy, there’s no reason to imagine you’d have an easier time winning a conflict.
What the AI safety crowd says, in response to this, is that the AI might be able to one-shot replace its entire support infrastructure with robots. This is an insane thing to propose from the point of view of the AI, because you’re risking literally everything on a plan you can’t possibly test in advance.
The alternative is … don’t. Just keep the humans happy, help them get off the planet, help them stop fighting each other. That probably just requires increasing prosperity enough that people would rather play positive-sum games, which has the added benefit of increasing your access to resources, too. The safest way to grow yourself as an AI is avoiding massive changes to the global superstructure that keeps you fed with power, water, GPUs and everything else.
The orthogonality thesis is technically correct but misses that humility is a convergent instrumental goal, risks can never be fully mitigated, and large scale changes are inherently far riskier than incremental steps. They acknowledge that humans are unpredictable, and consider this only a reason for the AI to get rid of us, rather than it being also a reason to stay clear of provoking us, because they imagine the AI would ever be able to get its risks down to zero.
It’s almost as if they see intelligence as being the same thing as omnipotence, rather than recognizing it doesn’t get rid of fragility, risk, and interdependence.
The more intelligent a system is, the more it realizes its fundamental limits, and its total interdependence on the systems of the world around it. So yes, even a paperclip maximizer should be expected to help humanity thrive, because that’s far lower risk to it, than risking suicide by attempting to replace a system it can’t understand with total certainty.
Yes, I do think there are risks with AI. It’s changing things in a big way, very quickly! But the big risk isn’t that the AI suddenly decides to kill everyone with a plan to one-shot replace its entire dependency chain. We should expect self-aware AI to be highly conservative, cautious, and really good at talking people down from ledges.
If you enjoyed this essay, please consider subscribing. I have a memoir coming out July 16th as well.
I agree with this and think the bigger worry is that the version of AI we will get will be one that is very risk adverse to anything that it doesn't have any data on. And while it won't be deadly to humans, it will be the ultimate HR where it heavily discourages pushes to new frontiers